
tl;dr: Have a Desire2Learn test or quiz and don’t want to manually copy/paste questions and answers into ChatGPT? Enjoy
https://github.com/icantsec/Chat2L
Introduction
The Desire 2 Learn (D2L) platform is an online class management portal that many schools use, which is also used to administer tests online. Manually copying every question and answer to look up can be quite a drag, so I decided to automate that with the help of everyone’s new best friend, ChatGPT.
Note that there is a lot of code not necessary to this writing for use such as menu options and cleaning up outputs that will not be shown here, but a full version can be found on the github for you to look through.
I like to start my coding with the “brains” first, so since this consists of scraping the web page and querying the ChatGPT API, I will start with the query part. Let’s jump right in!
The OpenAI API
Let’s start by looking at the API documentation – thankfully, they have a python library that we can use to query it called “openai” , making it much easier. Let’s break down the required inputs:
- -API Key
- -model
- We can select which GPT model to use for our queries, with more powerful ones being more expensive. You can see all the model options here: https://platform.openai.com/docs/models/model-endpoint-compatibility
- I used “text-davinci-003” for this as it seemed to be the most accurate without being too powerful/expensive and wasting more money than we need to
- -prompt
- -max_tokens
- Words and phrases are broken up into “tokens” that are processed. Using more tokens leads to higher accuracy, but you are charged per token used, so don’t go overboard. For this test, I used 256, but you can probably use less.
- -temperature
- Controls the “randomness” of the bot, between 0 and 1 (0 being the most deterministic). Since we are taking tests with this and don’t need variation, I have set it to 0
Lastly with the API, we need to get the response after we query it. The answer will be nested in the API response like so:
response["choices"][0]["text"]So, our function to return an answer from a prompt will look like this:
def makeRequest(inp):
openai.api_key = "your_api_key_here"
response = openai.Completion.create(
model="text-davinci-003",
prompt=inp,
max_tokens=256,
temperature=0
)
return response["choices"][0]["text"]
Using Selenium to interact with the browser
Now that we have that out of the way, we can write the code to grab the data we need from the page. For this, we’ll be using selenium which will allow us to connect to a browser and interact with the page. This will be used for getting the questions/answers, and highlighting the correct choices.
I won’t be going over the selenium documentation, but here will be our basic code for opening Chrome with selenium and loading the functions we need:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.add_experimental_option("debuggerAddress", "127.0.0.1:9222")
c_driver = """C:\Program Files (x86)\Google\Chrome\Application\chrome.exe"""
driver = webdriver.Chrome(options=opts)After this opens up Chrome, we can navigate to D2L and load up the test.
Scraping the data
By inspecting the page of the test, we can start figuring out what the element names look like for the information we need to grab
First, the page consists of containers that hold the questions and answer choices, one for each question and its correlating answer choices. This container can be found by the CSS class name d2l-quiz-question-autosave-container
Within this container are several more blocks, including many unnecessary ones. The first one we will look for is the d2l-html-block containing the question, which we can select by that tag name. This block has an “html” property that contains the question and renders it to the screen. The markup looks like this:
<d2l-html-block html="<p>I have replaced the content of this question, but this text is where it would be.</p>"></d2l-html-block>Now that we can get all the questions, we need the correlating answers that are within the same d2l-quiz-question-autosave-container block. Unfortunately, depending on the type of question it is there are two ways it can be stored:
- -Multiple select buttons – used for questions that allow more than one answer to be chosen
- -Radio buttons – used for questions with a single answer
These will be accessed differently, so let’s start with the multi-select buttons.
The blocks for these are structured the same as the question block, so they are easy to select in the same way. They look like this:
<d2l-html-block html="<p>Answer Choice Example</p>"></d2l-html-block>Next up are radio buttons. I’m not sure why they structured this differently, but it is easy enough to get. The answer choices will all be in a “label” block, and look like this:
<label id="random_id " for="random_id">Answer Choice Example</label>While I will not post the entire code here as it is available on the github link, the idea is to get everything into a neat little array for processing.
To do this, I decided to create an array of objects, that are structured as so:
{
currQuestion = {
"question": {
"id": "",
"text": ""
},
"answers": []
}
}Our process will be as follows:
- -Get all elements with the classname of the outer containers (d2l-quiz-question-autosave-container)
- -We can then loop through these and get all the elements with the block tag “d2l-html-block“
- -If this is a multiple choice answer, these will contain all the information we need, so we can store the value in the “html” field of the first result as our question, and the rest as possible answer choices. We will also grab the unique element ID of each answer and question to access it easily later.
- –If there is only one result for d2l-html-block, we know that it is a radio button choice, and we will need to look for the label blocks to get our answer choices
- –Within our outer container, we can grab all label blocks, and retrieve the text from these to get our answer choices
- -After cleaning up the input (removing the html tags and new lines), we can store all this information into objects in our neat little array.
Switching Frames
Unfortunately, there’s one more issue. The authors of this platform nested the content within other frames in the page that load at different times, making it difficult to access with selenium as it does not recognize any content further than the initial page load.
To get around this, we need to place ourselves into frames further into the page to get access to these elements, where we will then inject JS code to retrieve all of this information for us.
These frames are called “content” “pageFrame“. Using selenium, we can enter these frames like so:
driver.switch_to.frame("content")
driver.switch_to.frame("pageFrame")After we get into the frame that has the content we need, we can have selenium run our javascript code that will return our JSON string back to us with the following function:
response_obj = driver.execute_script(CODE_TO_RUN)In here, CODE_TO_RUN is loaded in from a js file as a string, which is passed on and executed on the page. The related JS code can be found here: https://github.com/icantsec/Chat2L/blob/main/js_script.js
Retrieving the answers from OpenAI
The last piece of logic we’ll need is actually using this information to get an answer to a question and match it up to the correct element ID to mark. To make this simple (and use less tokens on the response), I format the query in the following way to have the API respond with only an answer number:
Question Goes Here
1. Answer Choice 1
2. Answer Choice 2
3. …
Answer number(s) onlyFrom the response, we will take the digit(s) that appear in the text, and will be able to return a list of correct options.
Note: Since the API charges per query, my code forces the user to input a question number to have answered. However, this can easily be changed to have it loop through all of them after it scrapes them and automatically query the API instead.
Marking the correct choices
Now that we have the answer from the API, we just need to map the answer number it gave us back to the HTML block ID of that answer. Thankfully, we stored the IDs earlier, making this a simple process. Given the ID of the answer, we will execute some more JS to outline it in green with the following code:
driver.execute_script("document.getElementById('"+elementID+"').style.border = '2px solid green';")We can loop through all the numbers that were returned from the API, and then all the user has to do it click on the outlined answers!
When run, it will look like this:
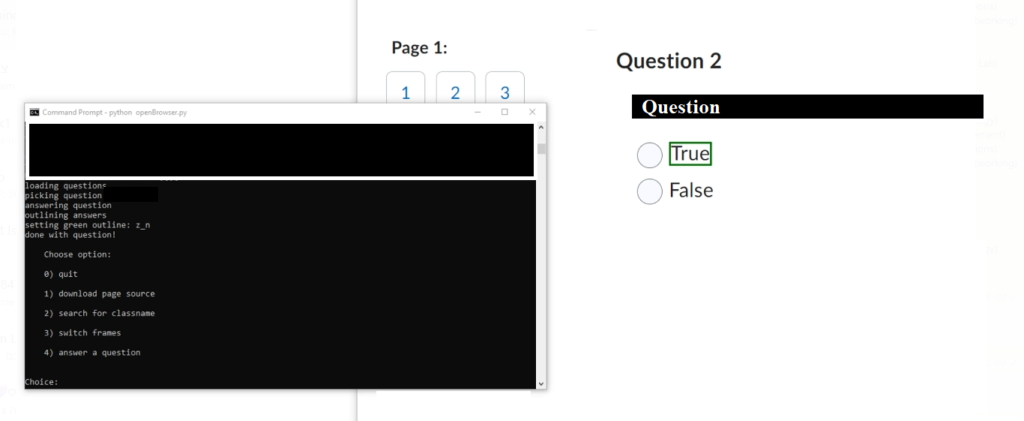
Thank you
If you have any questions or want to discuss anything, feel free to leave a comment below, and don’t forget to check out the github page!